
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- guru
- docker
- BAEKJOON
- function
- 백준
- 코어 이더리움 프로그래밍
- rust
- Thread
- 전문가를 위한 파이썬
- Fast API
- 블록체인
- RabbitMQ
- 러스트
- dockerfile
- BlockChain
- Refactoring
- IMAGE
- 알고리즘
- fluent python
- 동시성
- 플랫폼
- Python
- Container
- AWS
- 파이썬
- Network
- 이더리움
- Kubernetes
- Ethereum
- Algorithm
- Today
- Total
| 글쓰기 | 방명록 | 관리 |
Victoree's Blog
Elasticsearch를 아십니까? 본문
들어가며..
평소 유저향 서비스 개발을 5년째 해오고 있는 나는 API 서버 개발, CICD 배포 관리나 인프라 리소스 관리 등등을 해오곤 했는데, 아직 검색 엔진을 기반으로 한 검색 기능이나 추천 기능을 구현해 볼 기회가 없었다. 이번 프로젝트는 아직 경험해보지 못한 검색/추천 기능들을 직접 해볼 기회가 있고, 이를 대상으로 할 데이터 셋도 크고 사용자 트래픽도 꽤 받아볼 수 있는 기회라고 판단해서 현재 열심히 출시 준비를 하고 있다.
검색과 관련한 기능을 곧 맡아서 개발해야 하기 때문에, 요즘 검색엔진 공부를 하고 있고 이렇게 글을 적게 되었다 🙂
이 글은 말이죠~
Elasticsearch(검색 엔진)가 어떤 역할을 하는 녀석인지 감이 안 오는 사람, Elasticsearch에서 해주는 기능들이 어떤 게 있는지 궁금한 사람을 대상으로 적어보았다.
이번 글에서는 간단히 Elasticsearch에 대한 개념과 용어들, 알아야 할 사항들에 대해 소개하겠다.
엘라스틱 서치
Elasticsearch는 실시간으로 데이터 검색과 분석을 가능하게 하는 오픈 소스 분산형 검색 엔진이다. JSON 형식의 문서를 사용하여 데이터를 저장하고, REST API를 통해 접근이 가능하다. 엘라스틱 서치는 루씬(Lucene) 라이브러리를 기반으로 구축되었으며, 텍스트, 숫자, 날짜, 지리적 위치 데이터 등 다양한 유형의 검색을 지원하고 그중에서도 텍스트 분석에 특화되어 있다.
ES는 Nosql의 일종으로 분류할 수 있고, 분산 처리를 통해 실시간성으로 빠른 검색이 가능하다. 기존 RDBMS의 데이터 구조로 처리하기 힘든 대량의 비정형 데이터 검색이 가능하며(검색용 Document 모델링을 따로 작업한다) Full Text 검색과 구조 검색을 모두 지원한다.
→ 즉 하나의 검색용 서버가 뜬다고 생각하면 된다. API 서버에서 우리가 원하는 쿼리로 ES를 찔러 원하는 결과값을 받아 정제해서 리턴하는 플로우랄까.
검색엔진이지만 MongoDB나 Hbase 같은 대용량 스토리지로 활요하는 케이스도 있다고 한다. 로그 분석, 실시간 모니터링, 데이터 분석 등 다양한 용도로 널리 사용되며, ELK 스택(Elasticsearch, Logstash, Kibana) 중 분석과 저장을 담당한다.

엘라스틱 서치를 쓰는 이유!
기존 RDBMS 기반 어플리케이션에서는 텍스트 검색을 적용하기 어렵다. `LIKE` 를 사용한 와일드카드 검색은 문자열의 일부분을 검색할 때 전체 데이터를 순차적으로 스캔하기 때문에 큰 데이터셋에서 성능 저하를 일으킬 수 있다.
또한 LIKE 검색은 정확한 일치 또는 단순 패턴 매칭에 유용하지만, 복잡한 검색 조건이나, 텍스트 분석, 유사도 검색 등 고급 기능을 지원하지 않는다는 한계가 있다.
ES는 유의어 처리, 동의어 매칭, 풀텍스트 검색과 같은 고급 검색 기능을 지원하기 위해, 텍스트 데이터를 받아 토크나이징과 형태소 분석을 수행한다. 문서 내 텍스트를 단어 단위로 분리하고(토크나이징), 의미 없는 조사나 불용어를 제거함으로써, 각 문서에서 의미 있는 데이터를 추출한다. 추출된 데이터를 바탕으로, 특정 검색어에 대해 유사도 점수를 계산하여 가장 관련성 높은 문서를 찾아낸다.
이 밖에도 문서의 중요도를 평가하고, 검색 결과의 순서를 결정하기 위해 키워드에 가중치를 부여하는 기능이나 형태소 분석과 불용어 제거를 거친 텍스트로부터 의미 있는 키워드를 추출하고, 이를 문서별로 인덱싱을 하는 등의 기능들이 있다.
엘라스틱 서치를 사용하는 예시로 어떤 서비스 기능들이 있을까?
우선, 모두가 쉽게 떠올릴 수 있는 구글과 네이버 같은 통합 검색엔진이 있을 것이다. 위 같은 통합 검색엔진은 인터넷상의 웹페이지들을 크롤링하여 인덱스를 생성하고, 사용자가 입력한 키워드에 가장 잘 매치되는 결과를 랭킹에 따라 제시한다.
Netflix, Spotify, YouTube 등의 스트리밍 서비스에서도 사용자가 원하는 영화, 음악, 비디오 등을 쉽게 찾을 수 있도록 검색 엔진이 사용된다. 콘텐츠 스트리밍 서비스에서는 사용자의 시청 또는 청취 기록, 선호도(좋아요, 별로예요 같은 평가 기반), 트렌드 데이터를 활용하여 개인화된 검색 결과와 추천을 제공한다.
마지막으로, 지도 서비스에서도 검색 엔진이 사용된다. 사용자가 특정 장소, 주소, 랜드마크 이름을 입력했을 때, 검색 엔진으로 해당 위치의 지도상 좌표와 정보를 빠르게 찾아낼 수 있도록 한다. 검색 엔진에 쿼리를 날릴 때, 이름의 일치에 높은 스코어를 부여하고, 지리적으로 사용자의 현 위치와 먼 곳은 점수를 낮게 매겨 목록을 내려주는 등의 방법으로 장소 리스트를 내려줄 수 있다.
ES에서 알아야할 주요 개념들에 대해 살펴보자
1. 역인덱스- Inverted index

역인덱스란 특정 단어가 어떤 문서에 위치하는지 저장하는 자료 구조이다.
| 단어 | DocumentID |
| 검색 | 1, 2 |
| Elasticsearch | 10 |
| System | 1, 2, 10 |
| Uplus | 8 |
역인덱스를 기반으로 검색을 처리하면 속도가 LIKE 검색보다 매우 빨라진다. 위에서 간단히 이야기했었지만, 예시를 통해 한번 더 설명하자면.
SELECT doc_id
FROM documnets
WHERE doc_content LIKE '%system%';
해당하는 모든 문서를 찾으려면 모든 열(row)의 내용에 대해서 LIKE를 수행하기 때문에 데이터가 늘면 늘수록 속도가 현저히 떨어진다는 단점이 있다.
반면 역색인 구조를 생성해 두면, 키워드 색인을 통해 문서 ID를 바로 찾을 수 있다.
2. 인덱싱 - 토큰나이징 [N-gram]
ES나 자연어 처리에서 토크나이징을 하는 주된 이유는 복잡한 텍스트 데이터를 더 작은, 검색 가능한 단위로 분리하여 효율적인 검색과 분석을 가능하게 하기 위함이다. 토크나이징을 통해 문서 내에서 키워드를 인덱싱 하고, 이 키워드들을 형태소 분석 같은 처리 과정을 거치면, 어근 추출(stemming)이나 동의어 처리 기능을 구현할 수 있다.
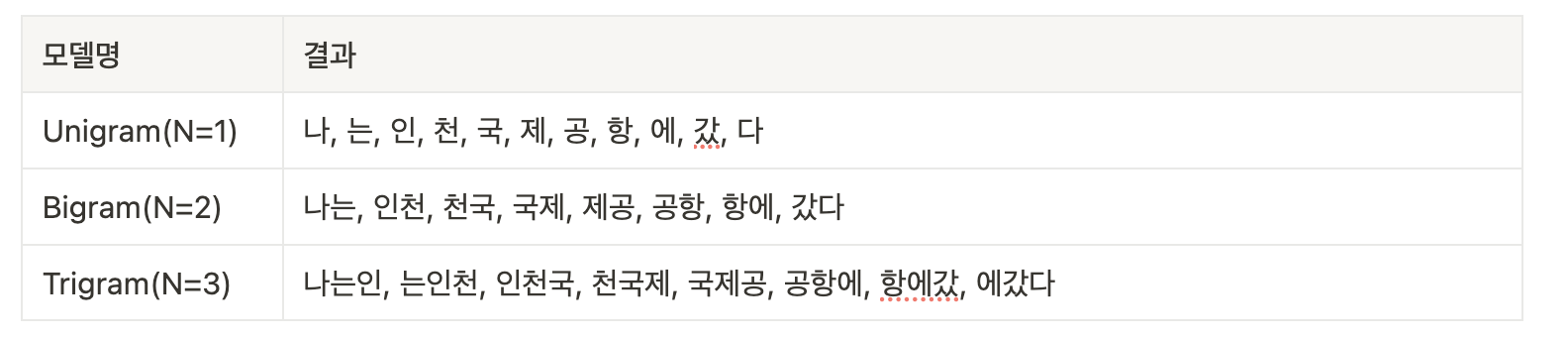
하지만 토크나이징에는 치명적인? 단점이 있다. 정확도 문제가 생긴다는 점인데, 위 예시를 보면 Bigram을 적용했을 때 천국을 검색해도 해당 문서가 검색 결과에 나올 수 있다. 이러한 이유로 검색을 수행했을 때, 문맥에 맞는 컨텍스트가 결과로 나오는 것이 중요한 서비스에서는 토크나이징을 잘 적용하지 않는다고 한다. 형태소 분석을 빠르게 적용할 수 있거나 사전 관리를 담당하는 팀이 있으면 N-Gram은 잘 사용하지 않는다. 형태소 분석기나 사전 관리를 하기 어려운 팀의 경우 어쩔 수 없이 N-Gram을 적용한다고.. 😢
3. 인덱싱 - 형태소 분석
인덱싱을 할 때, 검색어의 형태소를 분석하여 적용하는 방법이 있다. 토크나이징과 비교하여 문장의 의도와 부합하는 키워드를 등록할 수 있다는 장점이 있으나 생각처럼 잘 되지 않는다는 단점이 있다..
한국어는 어순이 자유롭고, 하나의 단어가 여러 형태소로 구성될 수 있으며, 동일한 형태의 단어가 다른 의미를 가지는 경우가 많기 때문이다. 이 때문에 형태소 분석기의 정확도는 사용되는 알고리즘과 사전, 학습 데이터의 질에 크게 의존한다.
- 한국어 형태소 분석기를 만들기 어려운 이유
- 교착어
- 어절 유형의 다양성 - 어휘 형태소와 문법 형태소
- 음절을 자소 단위로 분할하여 원형을 복원해야하는 문제
- 형태론적 중의성
형태소 분리와 품사 중의성- “보고서” ⇒ ‘보고서’ : 체언 / ‘보’ : 용언 + ‘고서’: 어미
- “감기는” ⇒ ‘감기’ : 체언 + ‘는’: 조사 / ‘감기’: 용언 + ‘는’ : 조사
- 형태론적 변형
- 용언의 불규칙 활용 : 아름답다 → 아름다워
- 탈락과 축약 : 보아 → 봐
- 교착어
형태소 분석기는 확률 모델을 기반으로 만들어지는데, 한국어 형태소 분석기 중 유명한 Mecab은 (사실상 본래 일본의 Taku Kudo라는 분이 알고리즘은 개발해서 일본어 형태소 분석기) 은닉 마코프 모델(HMM)을 개선한 CRF(Condition Random Field)를 기반으로 만들어졌다.
형태소 분석 과정은 우선 검색어에서 분석 후보를 생성한다.
“나는 인천국제공항에 갔다” 를 예로 들면, 이 단어들을 다 쪼개서 분석 후보들을 생성하고, 이로부터 “나”라는 단어 이후에 나오는 “는”이라는 단어가 조사일지 아니면 “나는”이라는 고유명사일지 HMM 같은 확률 모델을 기반으로 최적의 후보를 선택하는 방식으로 분석이 진행된다고 한다.
ES와 RDBMS와 다른 용어
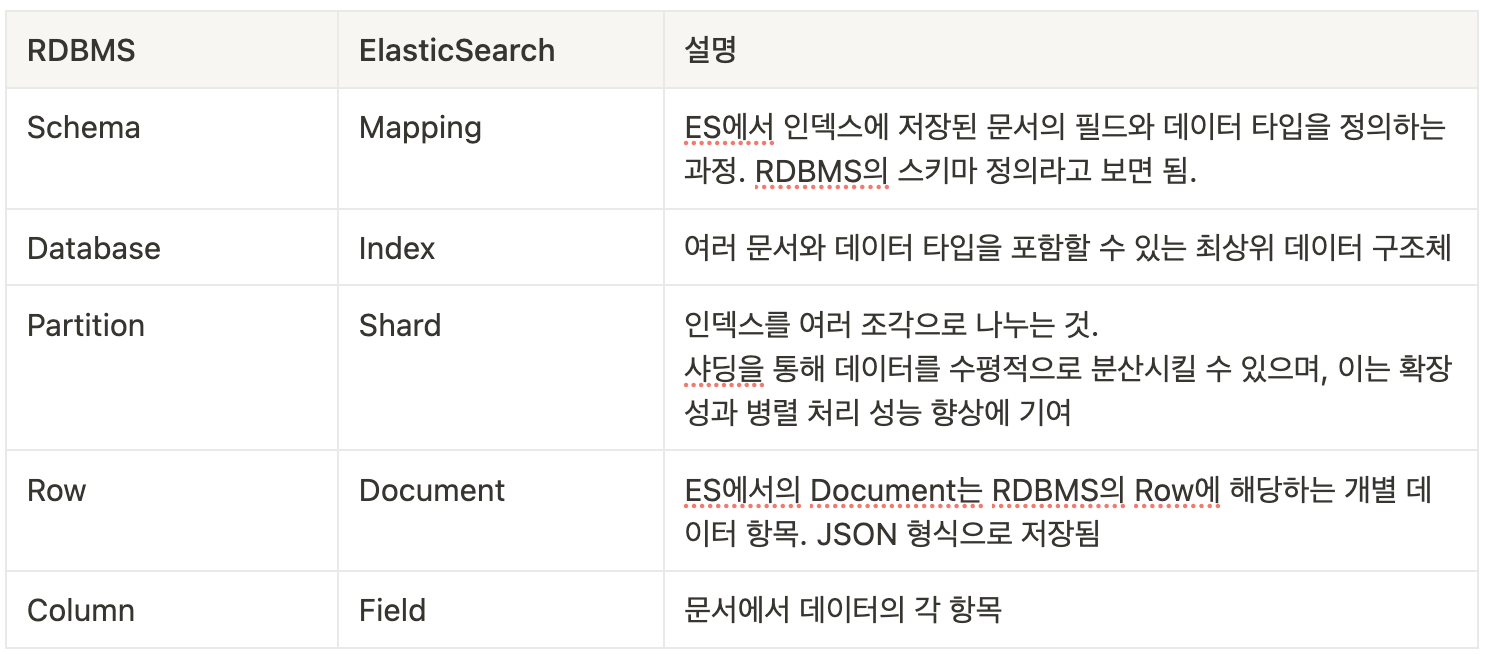
RDBMS와 검색엔진과 데이터 싱크를 맞추는 방법
데이터를 저장하고 관리하는 요소들이 분산되어있을 때, 캐시와 RDB와 싱크를 맞추는 이슈가 있듯 검색엔진과 RDBMS와의 데이터 싱크를 맞추는 것 역시 중요하다.
간단한 방법으로는, RDBMS에서 데이터를 추출하여 검색엔진에 주기적으로 전체 인덱싱(Full Indexing)을 적용하는 스크립트를 실행함으로써 전체 인덱스를 재구축하는 접근법이 있다. 하지만 이 방법은 데이터 양이 많으면 많을수록 풀 인덱싱을 수행하는 시간이 오래 걸리고, 인덱싱이 완료될 때까지 데이터 싱크에 일시적인 불일치가 발생할 수 있다. (Near Real Time..)
대안적인 접근법은, 어플리케이션 서버에서 데이터 변경 이벤트가 발생할 때마다 해당 이벤트를 검색 엔진에 즉시 반영하는 것입니다. 이 방법은 실시간에 가까운 데이터 동기화를 가능하게 하지만, 데이터를 변경할 수 있는 여러 주체가 있을 경우 (Service Application / Admin Application / CMS Application etc..), 각 출처에서 변경 이벤트를 관리해야 하고, 이로 인해 테스트와 유지보수가 복잡해질 수 있습니다.
이런 경우, 데이터베이스를 지속적으로 모니터링하면서 변경사항을 추적하는 중앙 집중식 시스템을 사용하는 방법을 적용하는 것이 나을 수 있다. 이 시스템은 데이터베이스의 변경 로그를 지속적으로 검사하고, 변경사항이 발견되면 해당 변경사항을 검색엔진에 자동으로 반영한다. 이 방식은 데이터 동기화 작업을 단일 시스템에서 관리할 수 있게 해 준다.
'Dev Circles > Ausg' 카테고리의 다른 글
| [AWGA] CloudFront (CDN) (0) | 2021.04.26 |
|---|---|
| [AWGA] S3 with Signed URL (0) | 2021.04.23 |
| [Big Chat] EKS란 무엇인가 (1) | 2021.04.23 |


